
二叉搜索树(Binary Search Tree)简称 BST,是二叉树的一种特殊形式。它有很多别名,比如排序二叉树、二叉查找树等等。
虽然二叉搜索树多年来一直作为算法面试的“必要考点”存在,但在实际面试中,它的考察频率并不能和常规二叉树相提并论,算不上“大热”的考点,同时考察内容也是相对比较稳定的。对于二叉搜索树,我们只要能够把握好它的限制条件和特性,就足以应对大部分的考题。
# 什么是二叉搜索树
树的定义总是以递归的形式出现,二叉搜索树也不例外,它的递归定义如下:
- 是一棵空树
- 是一棵由根结点、左子树、右子树组成的树,同时左子树和右子树都是二叉搜索树,且左子树上所有结点的数据域都小于等于根结点的数据域,右子树上所有结点的数据域都大于等于根结点的数据域
满足以上两个条件之一的二叉树,就是二叉搜索树。
从这个定义我们可以看出,二叉搜索树强调的是数据域的有序性。也就是说,二叉搜索树上的每一棵子树,都应该满足
左孩子 <= 根结点 <= 右孩子这样的大小关系。下图我给出了几个二叉搜索树的示例
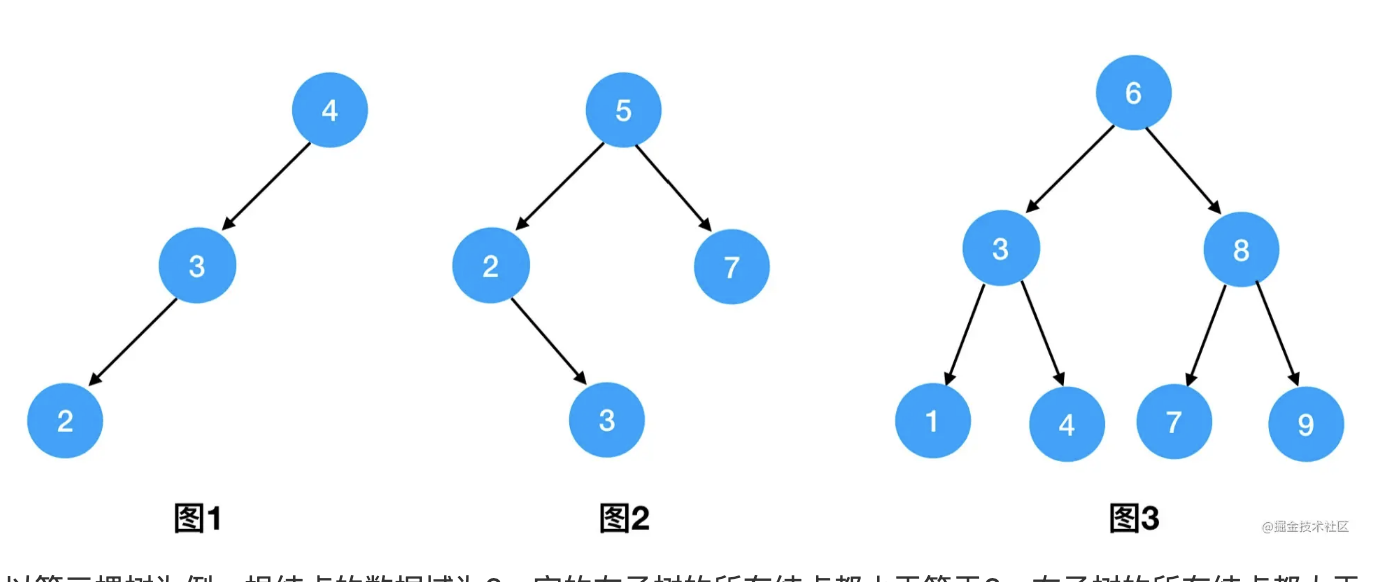
以第三棵树为例,根结点的数据域为6,它的左子树的所有结点都小于等于6、右子树的所有结点都大于等于6。同时在任意子树的内部,也满足这个条件——比如左子树中,根结点值为3,根结点对应左子树的所有结点都小于等于3、右子树的所有结点都大于等于3。
# 二叉搜索树:编码基本功
关于二叉搜索树,大家需要掌握以下高频操作:
- 查找数据域为某一特定值的结点
- 插入新结点
- 删除指定结点
# 查找数据域为某一特定值的结点
假设这个目标结点的数据域值为 n,我们借助二叉搜索树数据域的有序性,可以有以下查找思路:
- 递归遍历二叉树,若当前遍历到的结点为空,就意味着没找到目标结点,直接返回。
- 若当前遍历到的结点对应的数据域值刚好等于n,则查找成功,返回。
- 若当前遍历到的结点对应的数据域值大于目标值n,则应该在左子树里进一步查找,设置下一步的遍历范围为 root.left 后,继续递归。
- 若当前遍历到的结点对应的数据域值小于目标值n,则应该在右子树里进一步查找,设置下一步的遍历范围为 root.right 后,继续递归。
编码实现
function search(root, n) {
// 若 root 为空,查找失败,直接返回
if(!root) {
return
}
// 找到目标结点,输出结点对象
if(root.val === n) {
console.log('目标结点是:', root)
} else if(root.val > n) {
// 当前结点数据域大于n,向左查找
search(root.left, n)
} else {
// 当前结点数据域小于n,向右查找
search(root.right, n)
}
}
# 插入新结点
插入结点的思路其实和寻找结点非常相似。大家反思一下,在上面寻找结点的时候,为什么我们会在判定当前结点为空时,就认为查找失败了呢? 这是因为,二叉搜索树的查找路线是一个非常明确的路径:我们会根据当前结点值的大小,决定路线应该是向左走还是向右走。如果最后走到了一个空结点处,这就意味着我们没有办法再往深处去搜索了,也就没有了找到目标结点的可能性。
换一个角度想想,如果这个空结点所在的位置恰好有一个值为 n 的结点,是不是就可以查找成功了?那么如果我把 n 值塞到这个空结点所在的位置,是不是刚好符合二叉搜索树的排序规则?
实不相瞒,二叉搜索树插入结点的过程,和搜索某个结点的过程几乎是一样的:从根结点开始,把我们希望插入的数据值和每一个结点作比较。若大于当前结点,则向右子树探索;若小于当前结点,则向左子树探索。最后找到的那个空位,就是它合理的栖身之所。
编码实现
function insertIntoBST(root, n) {
// 若 root 为空,说明当前是一个可以插入的空位
if(!root) {
// 用一个值为n的结点占据这个空位
root = new TreeNode(n)
return root
}
if(root.val > n) {
// 当前结点数据域大于n,向左查找
root.left = insertIntoBST(root.left, n)
} else {
// 当前结点数据域小于n,向右查找
root.right = insertIntoBST(root.right, n)