
二叉搜索树是二叉树的特例,平衡二叉树则是二叉搜索树的特例。
# 什么是平衡二叉树
在上一节的末尾,我们已经通过一道真题和平衡二叉树打过交道。正如题目中所说,平衡二叉树(又称 AVL Tree)指的是任意结点的左右子树高度差绝对值都不大于1的二叉搜索树。
# 为什么要有平衡二叉树
平衡二叉树的出现,是为了降低二叉搜索树的查找时间复杂度。
大家知道,对于同样一个遍历序列,二叉搜索树的造型可以有很多种。拿 [1,2,3,4,5]这个中序遍历序列来说,基于它可以构造出的二叉搜索树就包括以下两种造型:
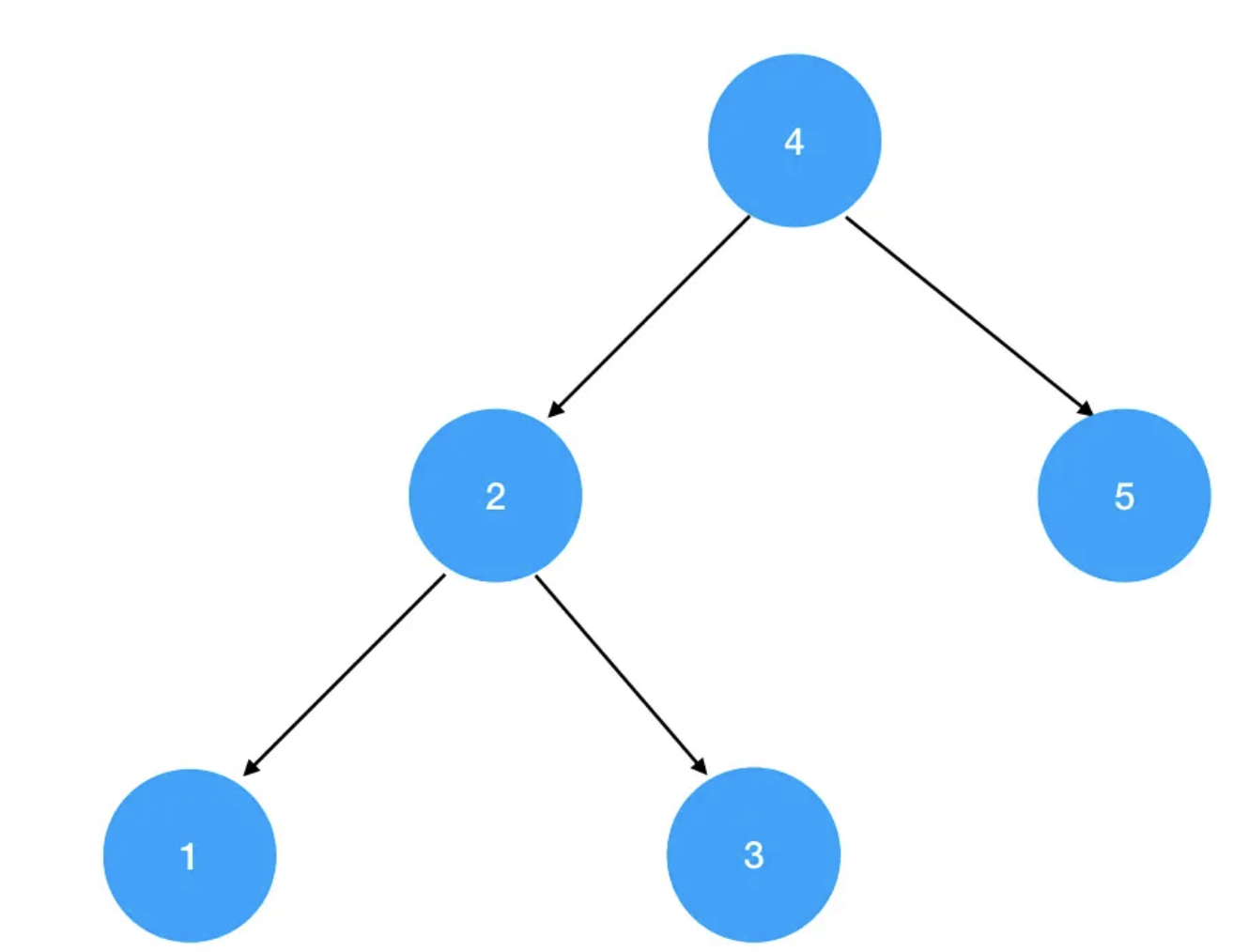
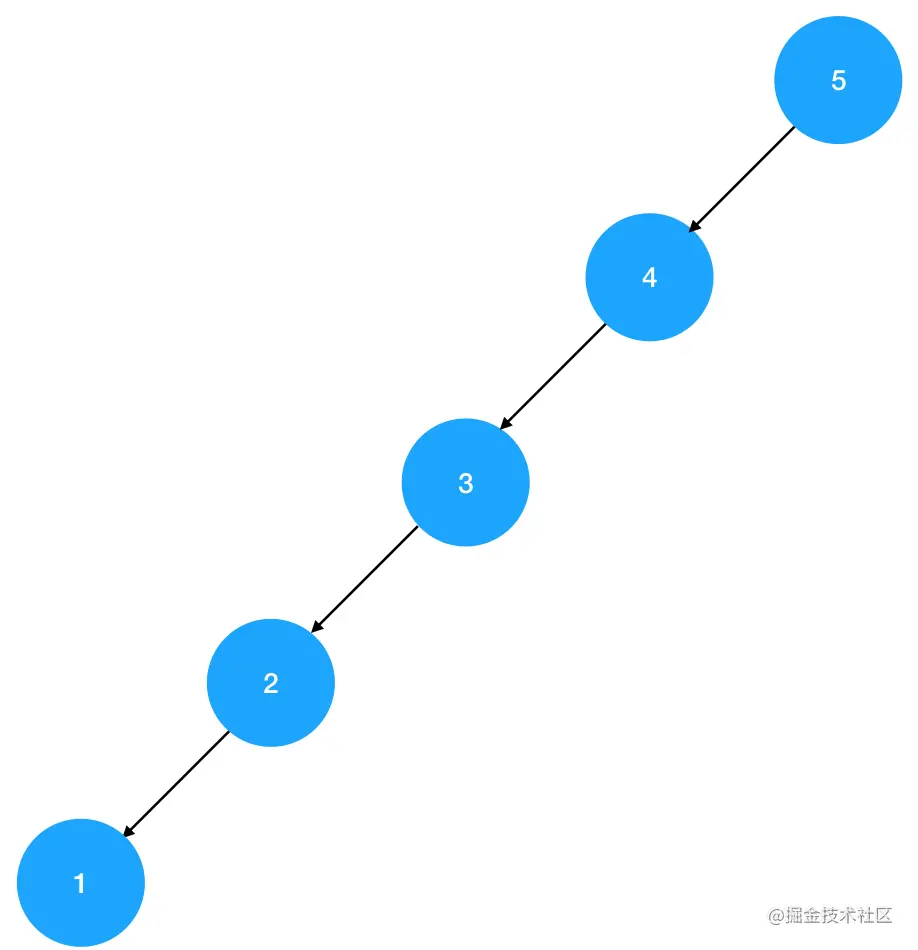
结合平衡二叉树的定义,我们可以看出,第一棵二叉树是平衡二叉树,第二棵二叉树是普通的二叉搜索树。
现在,如果要你基于上一节学过的二叉搜索树查找算法,在图上两棵树上分别找出值为1的结点,问你各需要查找几次?在1号二叉树中,包括根结点在内,只需要查找3次;而在2号二叉树中,包括根结点在内,一共需要查找5次。
我们发现,在这个例子里,对于同一个遍历序列来说,平衡二叉树比非平衡二叉树(图上的结构可以称为链式二叉树)的查找效率更高。这是为什么呢?
大家可以仔细想想,为什么科学家们会无中生有,给二叉树的左右子树和根结点之间强加上排序关系作为约束,进而创造出二叉搜索树这种东西呢?难道只是为了装x吗?当然不是啦。二叉搜索树的妙处就在于它把“二分”这种思想以数据结构的形式表达了出来。在一个构造合理的二叉搜索树里,我们可以通过对比当前结点和目标值之间的大小关系,缩小下一步的搜索范围(比如只搜索左子树或者只搜索右子树),进而规避掉不必要的查找步骤,降低搜索过程的时间复杂度。但是如果一个二叉搜索树严重不平衡,比如说上面这棵链式搜索树:
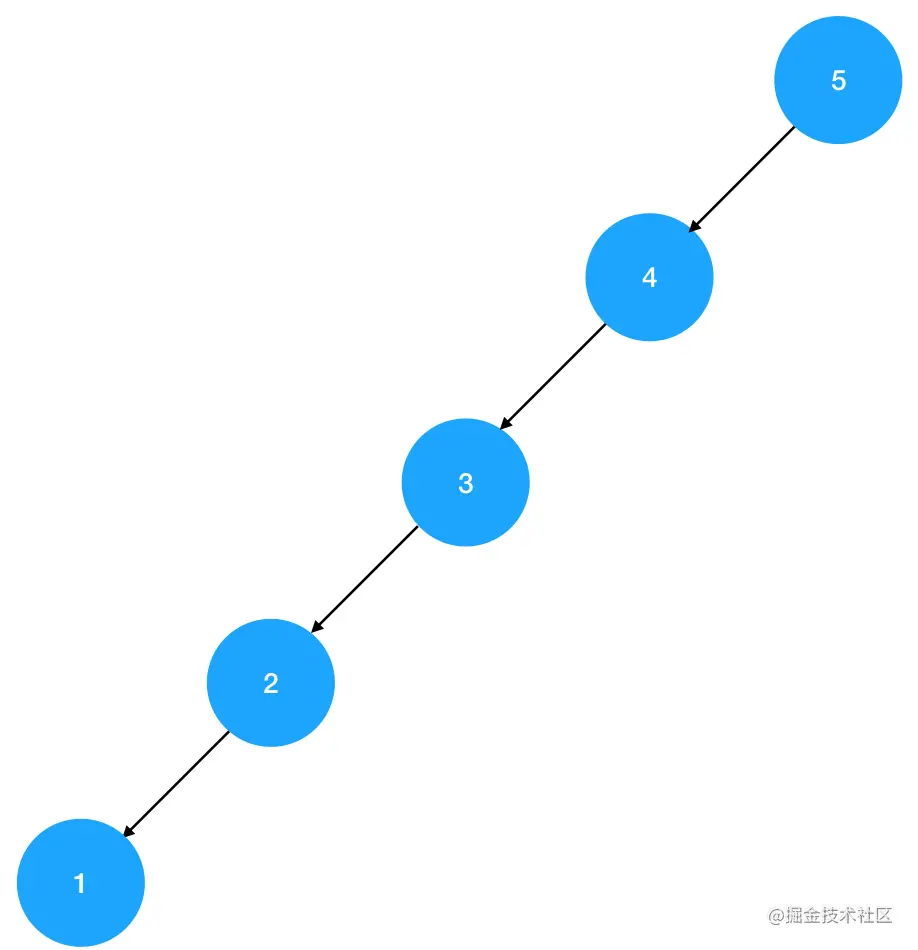
每一个结点的右子树都是空的,这样的结构非常不合理,它会带来高达O(N)的时间复杂度。而平衡二叉树由于利用了二分思想,查找操作的时间复杂度仅为 O(logN)。因此,为了保证二叉搜索树能够确实为查找操作带来效率上的提升,我们有必要在构造二叉搜索树的过程中维持其平衡度,这就是平衡二叉树的来由。
# 命题思路解读
平衡二叉树和二叉搜索树一样,都被归类为“特殊”的二叉树。对于这样的数据结构来说,其“特殊”之处也正是其考点所在,因此真题往往稳定地分布在以下两个方向:
- 对特性的考察(本节以平衡二叉树的判定为例)
- 对操作的考察(本节以平衡二叉树的构造为例)
平衡二叉树的判定 题目描述:给定一个二叉树,判断它是否是高度平衡的二叉树。
本题中,一棵高度平衡二叉树定义为: 一个二叉树每个节点 的左右两个子树的高度差的绝对值不超过1。
示例 1:
给定二叉树 [3,9,20,null,null,15,7]
3
/ \
9 20
/ \
15 7
返回 true 。
示例 2:
给定二叉树 [1,2,2,3,3,null,null,4,4]
1
/ \
2 2
/ \
3 3
/ \
4 4
返回 false 。
思路分析 来,我们复习一遍平衡二叉树的定义:
平衡二叉树是任意结点的左右子树高度差绝对值都不大于1的二叉搜索树。
抓住其中的三个关键字:
- 任意结点
- 左右子树高度差绝对值都不大于1
- 二叉搜索树
注意,结合题意,上面3个关键字中的3对这道题来说是不适用的,因此我们不必对二叉搜索树的性质进行校验。现在只看 1 和 2,先给自己一分钟思考一下——你可以提取出什么线索?
“任意结点”什么意思?每一个结点都需要符合某个条件,也就是说每一个结点在被遍历到的时候都需要重复某个校验流程,对不对? 哎,我刚刚是不是说了什么不得了的动词了?啊,是重复!是tmd的重复啊!!!来,学到了第18节,为了向我证明你没有跳读,请大声喊出下面这两个字:
递归!
没错,“任意结点”这四个字,就是在暗示你用递归。而“左右子树高度差绝对值都不大于1”这个校验规则,就是递归式。 啊,真让人激动呢,解决这道题的思路竟然已经慢慢浮现出来了,那就是:从下往上递归遍历树中的每一个结点,计算其左右子树的高度并进行对比,只要有一个高度差的绝对值大于1,那么整棵树都会被判为不平衡。
编码实现
const isBalanced = function(root) {
// 立一个flag,只要有一个高度差绝对值大于1,这个flag就会被置为false
let flag = true
// 定义递归逻辑
function dfs(root) {
// 如果是空树,高度记为0;如果flag已经false了,那么就没必要往下走了,直接return
if(!root || !flag) {
return 0
}
// 计算左子树的高度
const left = dfs(root.left)
// 计算右子树的高度